Topik klasifikasi data teks adalah topik yang luas dan sangat bermanfaat dalam berbagai bidang. Misalnya klasifikasi teks dalam melihat kencenderungan sentimen (positif-negatif), klasifikasi teks yang melihat apakah sebuah teks mengandung spam/tidak, dan dalam survei berkaitan pekerjaan, bisa digunakan untuk melihat KBLI (klasifikasi baku lapangan kerja) berdasarkan dari uraian pekerjaan, dsb.
Nah, di artikel ini, saya mencoba salah satu klasifikasi sederhana untuk mengkategorikan artikel berita, saya coba membagi hanya dua kategori saja ya. Dan saya pilih kategori olahraga dan finansial.
Memahami Perbedaan Olahraga dan Finansial
Alasan sederhana memilih dua kategori ini, adalah perbedaan yang sangat kentara yang biasanya terdapat di artikel berita. Maksudnya, tentu saja, kedua kategori ini sangat mencolok, sehingga nanti prakteknya, akan jauh mudah dikategorisasi oleh model. Misalnya kalau olahraga, biasanya terdapat kata olahraga, lapangan, kompetisi, sepak bola, berbagai cabang olahraga, sedangkan artikel finansial, biasanya banyak mengandung kata keuangan, pasar, ekonomi, saham, perbankan, dan sejenisnya.
Peran Klasifikasi Teks
Klasifikasi teks merupakan bagian dari Natural Language Processing (NLP) yang bertujuan untuk mengelompokkan dokumen ke dalam kategori tertentu berdasarkan isi teksnya. Dalam konteks pembahasan ini, klasifikasi membantu sistem untuk secara otomatis menentukan apakah sebuah artikel lebih relevan ke topik olahraga atau finansial. Hal ini bisa berguna misalnya untuk pengelolaan arsip berita.
Proses Klasifikasi Artikel Berita
Untuk kepeleruan ini, saya telah menyiapkan 974 artikel kategori finansial, dan 972 artikel kategori olahraga. Yang saya scrap langsung dari detik.com (detik finance dan detik sport). Artikel berita ini saya simpan dalam format txt dan disimpan di dua folder tergantung pada klasifikasinya. Kedua folder ini nantinya juga disebut sebagai label (label detik_finance dan label detik_sport).
c:/klasifikasi/
├── klasifikasi.py
├── detik_finance/
│ └── artikel1.txt
│ └── artikel2.txt
└── detik_sport/
└── artikel1.txt
└── artikel2.txt
Tahap klasifikasi
- Dimulai dengan membaca isi/konten artikel di kedua folder,
- Memasukkannya hasil pembacaan ke dalam dataset array teks dan array label, di mana array teks diperoleh dari konten artikel, sedangkan array label diperoleh dari nama folder.
- Membagi dataset menjadi data training dan data testing. Data training adalah dataset yang kita gunakan untuk pemodelan, sedangkan data testing adalah dataset yang digunakan untuk menguji model dan menghasilkan evaluasi.
- Lanjut dengan pemodelan klasifikasi dan menghasilkan model. Dalam artikel ini, kita menggunakan algoritma Naive Bayes. Algoritma ini dilatih menggunakan data training untuk mempelajari perbedaan pola antara kedua kategori.
- Setelah itu menguji model dan mengevaluasi model
- Menggunakan model untuk memprediksi kategori dari artikel baru
Representasi Teks dengan TF-IDF
Sebelum dilakukan pemodelan, teks harus diubah menjadi representasi numerik. Pada artikel ini digunakan metode TF-IDF (Term Frequency–Inverse Document Frequency). Metode ini memungkinkan algoritma memahami pentingnya suatu kata dalam dokumen tertentu dibandingkan dengan seluruh dokumen dalam dataset.
Term Frequency (TF)
Yaitu mengukur seberapa sering sebuah kata muncul dalam satu dokumen/artikel
Rumus sederhana:TF(t,d)=total kata dalam dokumen djumlah kemunculan kata t di dokumen d
Semakin sering kata muncul di dokumen, semakin besar nilai TF.
Inverse Document Frequency (IDF)
Mengukur seberapa unik atau jarang kata tersebut dalam seluruh dokumen.
Rumus:IDF(t)=log(df(t)N)
Keterangan:
- N = jumlah total dokumen
- df(t) = jumlah dokumen yang mengandung kata t
Semakin jarang kata muncul di seluruh dokumen, semakin besar nilai IDF.
Penerapannya TD-IDF pada klasifikasi artikel
Contoh kata : gol, pemain, pertandingan, liga, pelatih. Kata “gol” mungkin:
- Sering muncul di artikel olahraga
- Jarang muncul di artikel finansial
→ Nilai TF tinggi di dokumen olahraga, Nilai IDF tinggi (karena jarang di dokumen lain), TF-IDF tinggi. Sehingga kata “gol” menjadi ciri khas kategori olahraga.
Contoh kata: saham, investasi, inflasi, dividen, obligasi. Kata “saham”:
- Sering muncul di artikel finansial
- Jarang muncul di artikel olahraga
→ TF tinggi di finansial, IDF tinggi, TF-IDF tinggi. Sehingga menjadi penanda kuat kategori finansial.
Contoh representasi sederhana dalam bentuk matriks dari kata – kata yang telah diberikan skor TF-IDF.
| Dokumen | gol | pemain | saham | inflasi |
|---|---|---|---|---|
| Olahraga | 0.8 | 0.7 | 0.0 | 0.0 |
| Finansial | 0.0 | 0.0 | 0.9 | 0.85 |
Matriks tersebut yang kemudian menjadi input bagi algoritma klasifikasi.
Implementasi dengan Python
Berdasarkan pembahasan di atas, pada bagian berikutnya disajikan skrip Python dalam satu file yang mencakup: Proses pembacaan data, Training model Naive Bayes, Evaluasi model, Prediksi kategori artikel baru. File di beri nama klasifikasi.py dan diletakkan pada folder c:/klasifikasi
import os
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report, accuracy_score
import joblib
# =========================
# 1. Load dataset dari folder
# =========================
def load_dataset(base_path):
texts = []
labels = []
categories = {
"detik_sport": "olahraga",
"detik_finance": "finansial"
}
for folder, label in categories.items():
folder_path = os.path.join(base_path, folder)
for filename in os.listdir(folder_path):
if filename.endswith(".txt"):
file_path = os.path.join(folder_path, filename)
with open(file_path, "r", encoding="utf-8") as f:
text = f.read().strip()
if len(text) > 0:
texts.append(text)
labels.append(label)
return texts, labels
# =========================
# 2. Load data
# =========================
base_path = "" # ganti sesuai path Anda
X, y = load_dataset(base_path)
print(f"Total data: {len(X)} artikel")
# =========================
# 3. Split train & test
# test 20%, train 80%
# =========================
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# =========================
# 4. Buat pipeline model
# =========================
model = Pipeline([
("tfidf", TfidfVectorizer(
lowercase=True,
max_df=0.9,
min_df=2,
ngram_range=(1, 2)
)),
("clf", MultinomialNB())
])
# =========================
# 5. Training
# =========================
model.fit(X_train, y_train)
# =========================
# 6. Evaluasi
# =========================
y_pred = model.predict(X_test)
print("\n=== Akurasi ===")
print(accuracy_score(y_test, y_pred))
print("\n=== Classification Report ===")
print(classification_report(y_test, y_pred))
# =========================
# 7. Simpan model
# =========================
joblib.dump(model, "model_klasifikasi_artikel.pkl")
print("\nModel disimpan sebagai: model_klasifikasi_artikel.pkl")
Selanjutnya, untuk menjalankan program, ketik perintah python klasifikasi.py, lalu tekan Enter dan tunggu beberapa saat hingga proses selesai. Setelah itu, hasil klasifikasi akan ditampilkan seperti berikut.
Total data: 1915 artikel
=== Akurasi ===
1.0
=== Classification Report ===
precision recall f1-score support
finansial 1.00 1.00 1.00 192
olahraga 1.00 1.00 1.00 191
accuracy 1.00 383
macro avg 1.00 1.00 1.00 383
weighted avg 1.00 1.00 1.00 383
Model disimpan sebagai: model_klasifikasi_artikel.pklInterpretasi hasil di atas adalah. Didapatkan akurasi 100%. Yang berarti 100% prediksi pada data testing benar. Kemudian untuk testing dari 20% artikel (393 artikel), diperoleh juga pressisi 100%. Artinya: Semua artikel yang diprediksi sebagai “finansial” memang benar finansial. Semua yang diprediksi “olahraga” memang benar olahraga. Tidak ada false positive.
Recall = 1.00. Artinya: Semua artikel finansial berhasil ditemukan. Semua artikel olahraga berhasil ditemukan. Tidak ada false negative.
Secara teori: 100% akurasi sangat jarang terjadi pada klasifikasi teks nyata. Kemungkinan besar ini karena dataset memang sangat mudah dipisahkan karena perbedaan kosakata antar kategori sangat jelas dan kuat. Artikel olahraga cenderung mengandung kata-kata seperti “gol”, “pertandingan”, “liga”, dan “tim”, sedangkan artikel finansial sering memuat istilah seperti “rupiah”, “saham”, “IHSG”, dan “bank”. Jika perbedaan vocabularinya sangat tegas seperti ini, maka model akan sangat mudah mengenali pola masing-masing kategori. Sehingga wajar jika hasil klasifikasinya bisa sangat tinggi bahkan mendekati sempurna (100%).
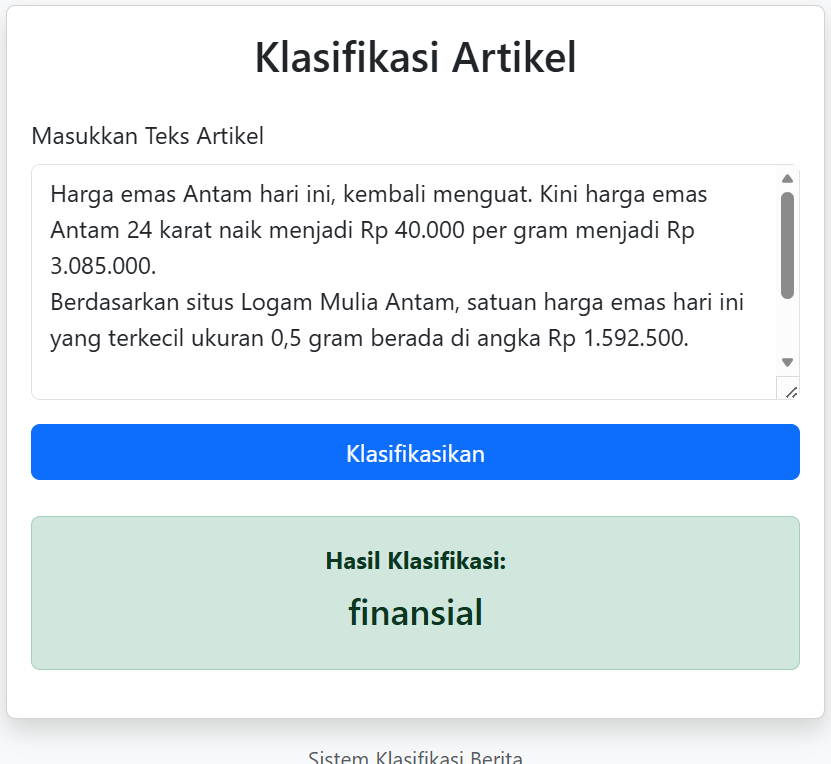
Demo Web Apps Klasifikasi Artikel
Untuk mempermudah pengujian, saya juga telah membuat web apps sederhana (berbasis flask python) yang sudah ditanamkan (embedded) model hasil training sebelumnya. Melalui aplikasi ini, Kita bisa langsung mencoba memprediksi kategori artikel hanya dengan memasukkan teks ke dalam teks area yang disediakan. Sistem akan secara otomatis mengklasifikasikan apakah teks tersebut termasuk kategori olahraga atau finansial.
Silakan coba langsung melalui tautan berikut: https://apps.wawasankita.com/klasifikasiartikel.
Sekian. Semoga bermanfaat.